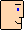 Data mining. Averiguar qué bancos van a quebrar en EEUU Data mining. Averiguar qué bancos van a quebrar en EEUU
La crisis financiera ha llevado a la quiebra a 140 bancos en EEUU en el año 2009, 157 en el 2010 y sigue todavía. La FDIC ha avisado de que hay 884 bancos en la "problem list" pero no dice cuales, por miedo a una "bank run" (pánico). Quedan 7973 bancos que a fecha de hoy no han quebrado... ¿como adivinar cuales son?. [la lista de quebrados ] [los datos].
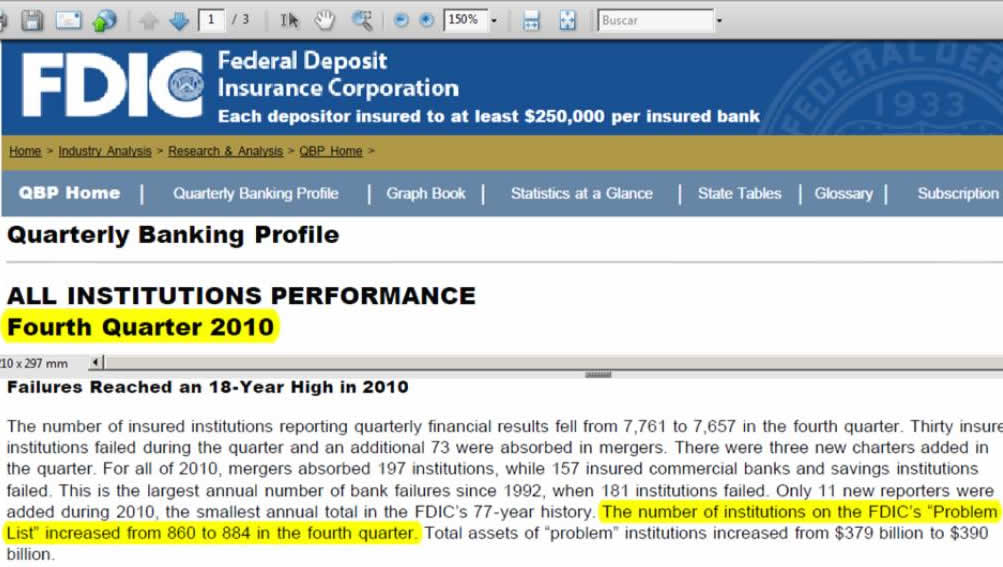
Tenemos 7973 bancos y 900 variables cada año, con información de 10 años. Una excel bastante grande...
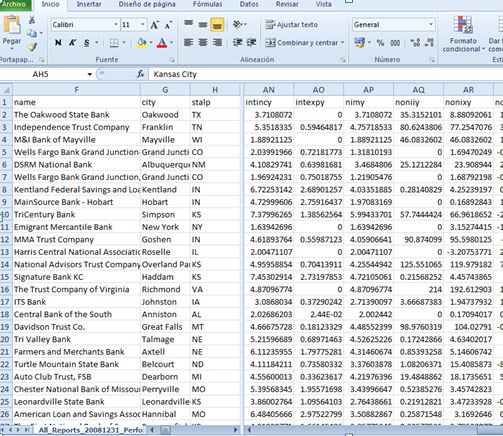
Usando técnicas de data mining (redes neuronales, c4.5, análisis discriminante, regresión logística, k-nearest neighbour...) encontramos exactamente 885 entidades en situación de riesgo. Vemos una imagen (en círculo rojo las buenas a la derecha y en triángulo verde las malas, a la izquierda):
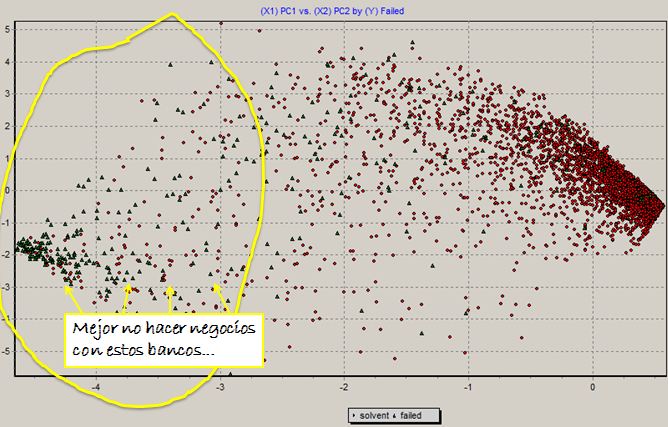
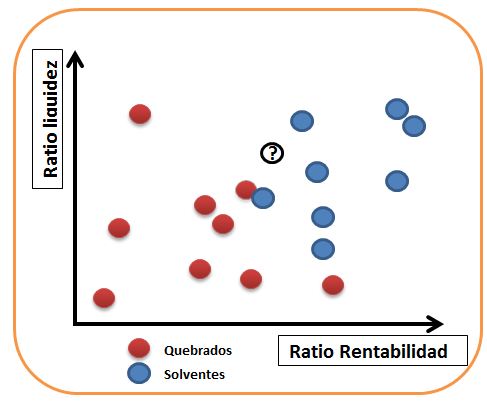
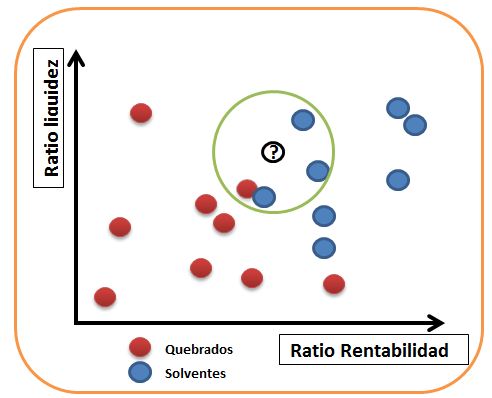
¿Como funcionan esos algoritmos?. Veamos por ejemplo el k-nearest neighbour (vecino más cercano). Ponemos todos juntos los quebrados -en rojo- y los solventes -en azul-. Como vemos los solventes son más rentables y tienen mejor ratio de liquidez. Ahora queremos analizar una nueva entidad, la que tiene un interrogante. Loque hacemos es mirar sus vecinos, en la figura de al lado hamos puesto un círculo verde. En ese círculo vemos que d elos 4 vecinos 3 son solventes y uno quebrado: el algoritmo lo clasifica como solvente.
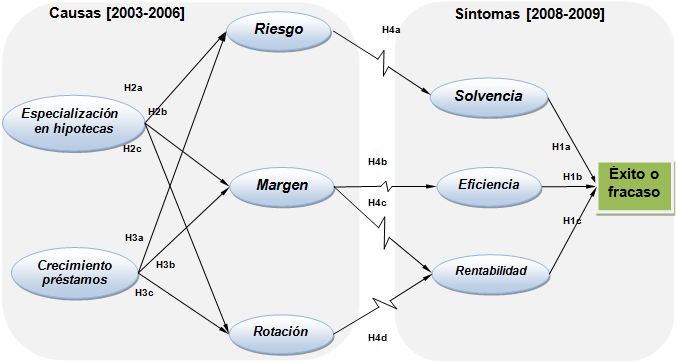
Tras el data mining, aplicando la técnica de ecuaciones estructurales planteamos un modelo causal para la quiebra bancaria:
|
 ¿Que relación
hay entre patatas fritas, cervezas, varones y día de la
semana?
¿Que relación
hay entre patatas fritas, cervezas, varones y día de la
semana?
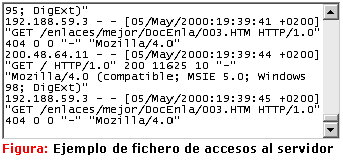 Destacan, por ejemplo, como modelos predictivos
las regresiones o modelos de red neuronal supervisada. Técnicas
de agrupamiento habituales son el análisis cluster y los
modelos neuronales de mapas autoorganizados. Para realizar segmentaciones,
son frecuentes los análisis discriminantes y la regresión
logística. Para detectar la afinidad, es decir, que una persona que alquila
una película de vídeo se lleva una caja de cervezas
y patatas fritas se
usan análisis de Fourier, generadores de asociaciones
de reglas y otras técnicas estadísticas. [
Destacan, por ejemplo, como modelos predictivos
las regresiones o modelos de red neuronal supervisada. Técnicas
de agrupamiento habituales son el análisis cluster y los
modelos neuronales de mapas autoorganizados. Para realizar segmentaciones,
son frecuentes los análisis discriminantes y la regresión
logística. Para detectar la afinidad, es decir, que una persona que alquila
una película de vídeo se lleva una caja de cervezas
y patatas fritas se
usan análisis de Fourier, generadores de asociaciones
de reglas y otras técnicas estadísticas. [