|
Lección Estadística |
Introducción al Análisis Clásico de Series de Tiempo
|
|
© Citar como: Arellano, M. (2001):
"Introducción al Análisis Clásico de Series de Tiempo", [en línea] 5campus.com,
Estadística <http://www.5campus.com/leccion/seriest> [y añadir
fecha consulta] |
1. Conceptos
Basicos De Series De Tiempo
1.2 Definición De
Serie De Tiempo
1.3 Primer Paso Al
Analizar Cualquier Serie De Tiempo
2. Modelos
Clasicos De Series De Tiempo
2.2 Estimación De
La Tendencia
2.3 Estimación De
La Estacionalidad
1. CONCEPTOS BASICOS DE SERIES DE TIEMPO
1.1 INTRODUCCIÓN
Toda institución, ya sea la familia, la
empresa o el gobierno, tiene que hacer planes para el futuro si ha de
sobrevivir y progresar. Hoy en día
diversas instituciones requieren conocer el comportamiento futuro de ciertos
fenómenos con el fin de planificar, prever o prevenir.
La planificación racional exige
prever los sucesos del futuro que probablemente vayan a ocurrir. La previsión, a su vez, se suele basar
en lo que ha ocurrido en el pasado.
Se tiene pues un nuevo tipo de inferencia estadística que se hace acerca
del futuro de alguna variable o compuesto de variables basándose en sucesos
pasados. La técnica más importante
para hacer inferencias sobre el futuro con base en lo ocurrido en el pasado, es
el análisis de series de tiempo.
Son innumerables las aplicaciones
que se pueden citar, en distintas áreas del conocimiento, tales como, en
economía, física, geofísica, química, electricidad, en demografía, en
marketing, en telecomunicaciones, en transporte, etc.
|
Series De Tiempo |
Ejemplos |
|
1. Series económicas: |
- Precios de un artículo - Tasas de desempleo - Tasa de inflación - Índice de precios, etc. |
|
2. Series Físicas: |
- Meteorología - Cantidad de agua caída - Temperatura máxima diaria - Velocidad del viento (energía
eólica) - Energía solar, etc. |
|
3. Geofísica: |
- Series sismologías |
|
4. Series demográficas: |
- Tasas de crecimiento de la
población - Tasa de natalidad, mortalidad - Resultados de censos
poblacionales |
|
5. Series de marketing: |
- Series de demanda, gastos,
ofertas |
|
6. Series de telecomunicación: |
- Análisis de señales |
|
7. Series de transporte: |
- Series de tráfico |
Uno de los problemas que intenta
resolver las series de tiempo es el de predicción. Esto es dado una serie {x(t1),...,x(tn)} nuestros
objetivos de interés son describir el comportamiento de la serie, investigar el
mecanismo generador de la serie temporal, buscar posibles patrones temporales
que permitan sobrepasar la incertidumbre del futuro.
En adelante se estudiará como
construir un modelo para explicar la estructura y prever la evolución de una
variable que observamos a lo largo del tiempo. La variables de interés puede ser macroeconómica (índice de
precios al consumo, demanda de electricidad, series de exportaciones o
importaciones, etc.), microeconómica (ventas de una empresa, existencias en un
almacén, gastos en publicidad de un sector), física (velocidad del viento en
una central eólica, temperatura en un proceso, caudal de un río, concentración
en la atmósfera de un agente contaminante), o social (número de nacimientos,
matrimonios, defunciones, o votos a un partido político).
1.2 DEFINICIÓN DE SERIE DE TIEMPO
En muchas áreas del conocimiento las
observaciones de interés son obtenidas en instantes sucesivos del tiempo, por
ejemplo, a cada hora, durante 24 horas, mensuales, trimestrales, semestrales o
bien registradas por algún equipo en forma continua.
Llamamos Serie de Tiempo a un
conjunto de mediciones de cierto fenómeno o experimento registradas
secuencialmente en el tiempo.
Estas observaciones serán denotadas por {x(t1), x(t2),
..., x(tn)} = {x(t) : t Î T Í R} con x(ti) el
valor de la variable x en el instante ti. Si T = Z se dece que la serie de tiempo
es discreta y si T = R se dice que la serie de tiempo es continua. Cuando ti+1 - ti
= k para todo i = 1,...,n-1, se dice que la serie es equiespaciada, en
caso contrario será no equiespaciada.
En adelante se trabajará con series
de tiempo discreta, equiespaciadas en cuyo caso asumiremos y sin perdida de
generalidad que: {x(t1), x(t2), ..., x(tn)}= {x(1), x(2), ..., x(n)}.
1.3 PRIMER PASO AL ANALIZAR CUALQUIER SERIE DE TIEMPO
El primer paso en el análisis de
series de tiempo, consiste en graficar la serie. Esto nos permite detectar las
componentes esenciales de la serie.
El gráfico de la serie permitirá:
a) Detectar Outlier: se refiere a puntos de la serie
que se escapan de lo normal. Un
outliers es una observación de la serie que corresponde a un comportamiento
anormal del fenómeno (sin incidencias futuras) o a un error de medición.
Se debe determinar desde fuera si un punto dado es outlier o no. Si se concluye que lo es, se debe omitir o reemplazar por otro valor antes de analizar la serie.
Por ejemplo, en un estudio de la
producción diaria en una fabrica se presentó la siguiente situación ver figura
1.1:
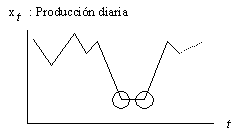 Figura 1.1
Figura 1.1
Los dos puntos enmarcados en un
círculo parecen corresponder a un comportamiento anormal de la serie. Al
investigar estos dos puntos se vio que correspondían a dos días de paro, lo que
naturalmente afectó la producción en esos días. El problema fue solucionado eliminando las observaciones e
interpolando.
b) Permite detectar tendencia: la tendencia representa el comportamiento predominante de la serie. Esta puede ser definida vagamente como el cambio de la media a lo largo de un periodo (ver figura 1.2).
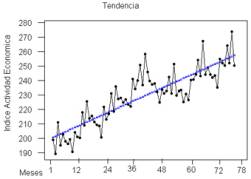
Figura
1.2
c) Variación estacional: la variación estacional representa
un movimiento periódico de la serie de tiempo. La duración de la unidad del periodo es generalmente menor
que un año. Puede ser un
trimestre, un mes o un día, etc (ver figura 1.3).
Matemáticamente, podemos decir que la serie representa variación estacional si existe un número s tal que x(t) = x(t + k×s).
Las principales fuerzas que causan una variación estacional son las condiciones del tiempo, como por ejemplo:
1) en invierno las ventas de helado
2) en verano la venta de lana
3)
exportación de fruta en marzo.
Todos estos fenómenos presentan un
comportamiento estacional (anual, semanal, etc.)
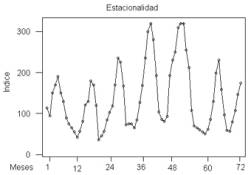 Figura 1.3
Figura 1.3
d) Variaciones irregulares
(componente aleatoria): los movimientos irregulares (al azar) representan todos los tipos de
movimientos de una serie de tiempo que no sea tendencia, variaciones
estacionales y fluctuaciones cíclicas.
2. MODELOS CLASICOS DE SERIES DE TIEMPO
2.1 MODELOS DE DESCOMPOSICIÓN
Un modelo clásico para una serie de
tiempo, supone que una serie x(1), ..., x(n) puede ser expresada como
suma o producto de tres componentes: tendencia,
estacionalidad y un término de error aleatorio.
Existen tres modelos de series de
tiempos, que generalmente se aceptan como buenas aproximaciones a las verdaderas
relaciones, entre los componentes de los datos observados. Estos son:
1. Aditivo: X(t) = T(t) + E(t) + A(t)
2. Multiplicativo: X(t) = T(t) · E(t) ·
A(t)
3. Mixto: X(t) = T(t) · E(t) + A(t)
Donde:
X(t) serie observada en instante t
T(t) componente de tendencia
E(t) componente estacional
A(t) componente aleatoria (accidental)
Una suposición usual es que A(t)
sea una componente aleatoria o ruido blanco con media cero y varianza
constante.
Un modelo aditivo (1), es adecuado,
por ejemplo, cuando E(t) no depende de otras componentes, como T(t),
sí por el contrario la estacionalidad varía con la tendencia, el modelo más
adecuado es un modelo multiplicativo (2).
Es claro que el modelo 2 puede ser transformado en aditivo, tomando
logaritmos. El problema que se
presenta, es modelar adecuadamente las componentes de la serie.
La figura 2.1 ilustra posibles
patrones que podrían seguir series representadas por los modelos (1), (2) y
(3).
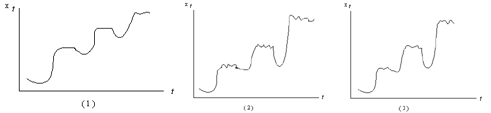
Figura 2.1
2.2 ESTIMACIÓN DE LA TENDENCIA
Supondremos aquí que la componente
estacional E(t) no está presente y que el modelo aditivo es adecuado,
esto es:
X(t) = T(t) + A(t),
donde A(t) es ruido blanco.
Hay varios métodos para estimar T(t). Los más utilizados consisten en:
1)
Ajustar
una función del tiempo, como un polinomio, una exponencial u otra función suave
de t.
2)
Suavizar
(o filtrar) los valores de la serie.
3)
Utilizar
diferencias.
2.2.1 AJUSTE DE UNA FUNCIÓN
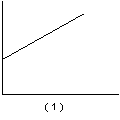
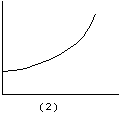
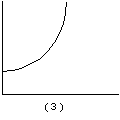
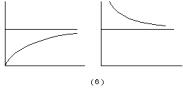
Los siguientes gráficos ilustran algunas de las formas de estas curvas.
|
1.T(t) = a + bt
(Lineal)
|
2.T(t) = a ebt (Exponencial)
|
3. T(t) = a + b ebt (Exponencial modificada)
|
|
4.T(t) = b0 + b1t ,...,+ bmtm (Polinomial) |
5.T(t) = exp(a + b(rt)) (Gompertz 0 < r < 1)
|
6. T(t) =
|

Nota:
i.
la
curva de tendencia debe cubrir un periodo relativamente largo para ser una
buena representación de la tendencia a largo plazo.
ii.
La
tendencia rectilínea y exponencial son aplicable a corto plazo, puesto que una
curva S a largo plazo puede parecer una recta en un período restringido de
tiempo (por ejemplo).
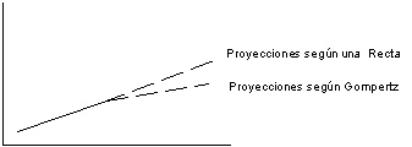
Figura 2.2
En la figura 2.2 ambas curvas (recta
y Gompertz) ajustan bien pero las
proyecciones divergen enormemente a largo plazo.
Ejemplo 1: En la tabla 2.1 se presentan los
datos trimestrales de unidades habitacionales iniciadas en los Estados Unidos
desde el tercer trimestre de 1964 hasta el segundo trimestre de 1972 [1]. (Es necesario advertir que para el
análisis de tendencia el periodo que se considera debería ser más largo. Sin
embargo, ya que el propósito principal es el de ilustrar el método de
descomposición y las técnicas para inferir partiendo de los elementos así
descompuestos, la insuficiencia de los datos no tiene por qué interesar.)
Tabla 2.1: Nuevas unidades habitacionales
comenzadas en los Estados Unidos del tercer trimestre de 1964 al segundo
trimestre de 1972 (en miles de unidades).
|
I |
II |
III |
IV |
Total
Anual |
|
|
1964 |
|
|
398 |
352 |
|
|
1965 |
283 |
454 |
392 |
345 |
1,474 |
|
1966 |
274 |
392 |
290 |
210 |
1,166 |
|
1967 |
218 |
382 |
382 |
340 |
1,322 |
|
1968 |
298 |
452 |
423 |
372 |
1,545 |
|
1969 |
336 |
468 |
387 |
309 |
1,500 |
|
1970 |
264 |
399 |
408 |
396 |
1,467 |
|
1971 |
389 |
604 |
579 |
513 |
2,085 |
|
1972 |
510 |
661 |
|
|
|
Fuente:
U.S. Department of Comerse, Survey of Current Bussiness.
Sea t cada uno de los 32 trimestres que van de 1964 a 1972, o sea que t = 1 para el tercer trimestre de 1964, t = 2 para el cuarto trimestre, y así
sucesivamente. Así que el dominio
de definición de t es el conjunto de
los enteros de 1 a 32 inclusive.
Sea T(t) las iniciaciones de
viviendas trimestralmente. Los
valores de t y T(t) se dan en la tabla 2.2.
Para calcular los valores de a
y de b en la recta de tendencia
T(t) = a + bt
Se obtienen las siguientes cifras a partir de los datos de la tabla 2.1.
Tabla 2.2: Cálculo de la tendencia de las
viviendas comenzadas en los Estados Unidos del tercer trimestre de 1964 al
segundo trimestre de 1972
|
Año trimestre |
t |
T(t) |
Tendencia |
|
1964: 3 |
1 |
398 |
291,73 |
|
4 |
2 |
352 |
298,07 |
|
1965: 1 |
3 |
283 |
304,41 |
|
2 |
4 |
454 |
310,75 |
|
3 |
5 |
392 |
317,09 |
|
4 |
6 |
345 |
323,43 |
|
1966: 1 |
7 |
274 |
329,77 |
|
2 |
8 |
392 |
336,11 |
|
3 |
9 |
290 |
342,45 |
|
4 |
10 |
210 |
348,79 |
|
1967: 1 |
11 |
218 |
355,13 |
|
2 |
12 |
382 |
361,47 |
|
3 |
13 |
382 |
367,81 |
|
4 |
14 |
340 |
374,15 |
|
1968: 1 |
15 |
298 |
380,49 |
|
2 |
16 |
452 |
386,83 |
|
3 |
17 |
423 |
393,17 |
|
4 |
18 |
372 |
399,51 |
|
1969: 1 |
19 |
336 |
405,85 |
|
2 |
20 |
468 |
412,19 |
|
3 |
21 |
387 |
418,53 |
|
4 |
22 |
309 |
424,87 |
|
1970: 1 |
23 |
264 |
431,21 |
|
2 |
24 |
399 |
437,55 |
|
3 |
25 |
408 |
443,89 |
|
4 |
26 |
396 |
450,23 |
|
1971: 1 |
27 |
389 |
456,57 |
|
2 |
28 |
604 |
462,91 |
|
3 |
29 |
579 |
469,25 |
|
4 |
30 |
513 |
475,59 |
|
1972: 1 |
31 |
510 |
481,93 |
|
2 |
32 |
661 |
488,27 |
Entonces, la recta de tendencia es
T(t) = 285,39 + 6,34× t
La figura 2.3 muestra gráficamente la recta de tendencia ajustada a los
datos trimestrales de la tabla 2.2.
La recta de trazos después de 1972 representa proyecciones (ver sección
3 Predicciones).
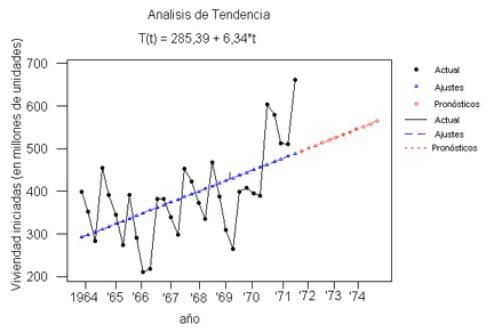
Figura 2.3
2.2.2 SUAVIZAMIENTO. FILTROS LINEALES
Una forma de visualizar la
tendencia, es mediante suavizamiento de la serie. La idea central es definir a partir de la serie observada un
nueva serie que suaviza los efectos ajenos a la tendencia (estacionalidad,
efectos aleatorios), de manera que podamos determinar la dirección de la
tendencia (ver figura 2.4).
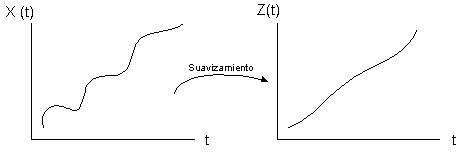
Figura 2.4
Lo que hacemos es usar una expresión
lineal que transforma la serie X(t) en una serie suavizada Z(t): Z(t)
= F(X(t)), t = 1,...,n
F
![]()
![]() X(t)
Z(t)
X(t)
Z(t)
de tal modo que F(X(t)) = T(t). La función F se denomina Filtro
Lineal. El filtro lineal más usado
es el promedio móvil.
2.2.2.1 PROMEDIOS MÓVILES
El objetivo es eliminar de la serie
las componentes estacionales y accidentales. Para una serie mensual con
estacionalidad anual (s = 12), la serie suavizada se obtiene,
![]() (1)
(1)
Para una serie trimestral, con
estacionalidad anual (s = 4), la serie suavizada está dada por
![]() (2)
(2)
A este procedimiento se les llama: filtro simétrico finito.
Nota: se suaviza cuando existen muchos cambios
bruscos, movimientos irregulares.
Ejemplo 2: A partir de los datos del
ejemplo1, se calcula un promedio móvil sumando los valores para un cierto
número de periodos sucesivos y dividiendo luego la suma así obtenida por el
número de períodos abarcados. En
este caso se trata de una serie trimestral y para ello se ocupa la fórmula (2).
Tabla 2.3: Cálculo del Promedio Móvil
centrado de cuatro trimestres de las iniciaciones de viviendas en los EEUU,
tercer trimestre 1964 a segundo trimestre de 1972 (en miles de unidades)
|
Año por trimestre |
Datos Originales Y |
Total Móvil en cuatro trimestres |
Promedio Móvil de cuatro trimestres |
Promedio Móvil Centrado de cuatro trimestres |
|
(1) |
(2) |
(3) |
(4) |
(5) |
|
1964: 3 |
398 |
|
|
|
|
4 |
352 |
|
|
|
|
1965: 1 |
283 |
1.487 |
372 |
371 |
|
2 |
454 |
1.481 |
370 |
369 |
|
3 |
392 |
1.474 |
369 |
367 |
|
4 |
345 |
1.465 |
366 |
359 |
|
1966: 1 |
274 |
1.403 |
351 |
338 |
|
2 |
392 |
1.301 |
325 |
308 |
|
3 |
290 |
1.166 |
292 |
285 |
|
4 |
210 |
1.110 |
278 |
276 |
|
1967: 1 |
218 |
1.100 |
275 |
287 |
|
2 |
382 |
1.192 |
298 |
314 |
|
3 |
382 |
1.322 |
331 |
341 |
|
4 |
340 |
1.402 |
351 |
359 |
|
1968: 1 |
298 |
1.472 |
368 |
373 |
|
2 |
452 |
1.513 |
378 |
382 |
|
3 |
423 |
1.545 |
386 |
391 |
|
4 |
372 |
1.583 |
396 |
398 |
|
1969: 1 |
336 |
1.599 |
400 |
395 |
|
2 |
468 |
1.563 |
391 |
383 |
|
3 |
387 |
1.500 |
375 |
366 |
|
4 |
309 |
1.428 |
357 |
348 |
|
1970: 1 |
264 |
1.359 |
340 |
342 |
|
2 |
399 |
1.380 |
345 |
356 |
|
3 |
408 |
1.467 |
367 |
382 |
|
4 |
396 |
1.592 |
398 |
424 |
|
1971: 1 |
389 |
1.797 |
449 |
471 |
|
2 |
604 |
1.968 |
492 |
507 |
|
3 |
579 |
2.085 |
521 |
536 |
|
4 |
513 |
2.206 |
552 |
559 |
|
1972: 1 |
510 |
2.263 |
566 |
|
|
2 |
661 |
|
|
|
En la tabla 2.3, por ejemplo, el
promedio móvil de cuatro trimestres para el primer trimestre de 1965 se obtiene
sumando los valores del tercer y cuarto trimestres de 1964 y el primero y
segundo trimestres de 1965 y dividiendo luego la suma por 4. El promedio para el segundo trimestre
de 1965 se obtiene sumando los valores del cuarto trimestre de 1964 con los del
primero, segundo y tercer trimestres de 1965 y luego dividiendo la suma por
4. Así pues, para cada promedio
sucesivo, se resta el trimestre que viene primero y se suma el último
siguiente.
La columna 4 de la tabla 2.3 muestra
los promedios móviles de cuatro trimestres obtenidos, partiendo de los datos iniciaciones de viviendas para el
1964 a 1972. El promedio móvil no
elimina las fluctuaciones muy acentuadas de la serie, pero reduce
sustancialmente la amplitud de las variaciones de los datos originales.
Si en el cálculo de un promedio
móvil entra un número impar de períodos, el proceso será más sencillo puesto
que el número de períodos antes y después del período para el cual se calcula
el promedio son iguales. Si el
número de periodos es par, como en este ejemplo, no se puede utilizar el mismo
número de períodos antes y después de un periodo especificado.
Por tanto, el promedio móvil ha de quedar a mitad de camino entre los
valores de dos períodos consecutivos y no se relaciona con ningún período. Este problema se puede resolver
calculando un promedio móvil centrado en la serie, lo cual se logra obteniendo
primero un promedio móvil centrado de dos trimestres de los promedios móviles
ya obtenidos. El primer promedio
móvil centrado es la media de los dos primeros promedios móviles de cuatro
trimestres, el segundo promedio móvil centrado es la media de los promedios
móviles de cuatro trimestres segundo y tercero, etc. De esta manera, habrá un número igual de períodos después y
antes del periodo especificado para el cual se está calculando el promedio
móvil centrado. Los promedios
móviles centrados se ven en la columna 5 de la tabla 2.3.
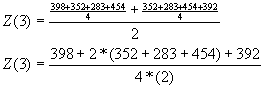
Según la fórmula 2, el cálculo sería
el siguiente:
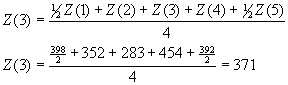
Este valor corresponde al Promedio
Móvil Centrado que se muestra en la columna 5.
La figura 2.5 muestra gráficamente el ajuste por a través del promedio móvil, según tabla 2.3, donde el segmento negro representa la serie original y el segmento azul la serie suavizada.
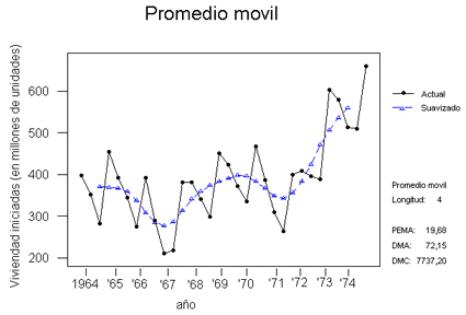
Figura 2.5
2.3 ESTIMACIÓN DE LA ESTACIONALIDAD
La estimación de la estacionalidad
no sólo se realiza con el fin de incorporarla al modelo para obtener
predicciones, sino también con el fin de eliminarla de la serie para visualizar
otras componentes como tendencia y componente irregular que se pueden confundir
en las fluctuaciones estacionales.
De acuerdo con los modelos de
descomposición (sección 2.1), se asume el siguiente modelo para T(t),
a)![]() Aditivo
Aditivo
b)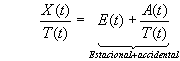 Mixto
Mixto
Una vez removida la tendencia se
obtiene los siguientes gráficos, donde en la figura 2.6 (a) aparece el modelo
aditivo y en la (b) el modelo mixto.
|
(a) |
(b) |
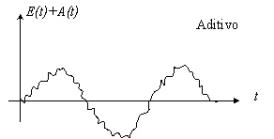
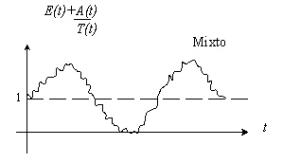
Figura 2.6
Pues si no hay tendencia, se espera
![]()
Como ![]() para serie
mensual, entonces basta estimar E(1),
E(2), E(3), ... , E(12). Para
una serie trimestral, bastaría conocer: E(1),
E(2), E(3) y E(4).
para serie
mensual, entonces basta estimar E(1),
E(2), E(3), ... , E(12). Para
una serie trimestral, bastaría conocer: E(1),
E(2), E(3) y E(4).
Suponga que se ha estimado la
tendencia por alguno de los métodos vistos en la sección previa. Sea ![]() la estimación de
la tendencia ya sea mediante una curva o filtros lineales. Entonces,
la estimación de
la tendencia ya sea mediante una curva o filtros lineales. Entonces,
- Si el modelo es aditivo
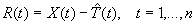 representa
la serie con los efectos de
tendencia removidos.
representa
la serie con los efectos de
tendencia removidos.
- Análogamente, si el modelo es mixto
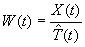 representa
la serie, una vez removidos los efectos de tendencia.
representa
la serie, una vez removidos los efectos de tendencia.
Estas series generadas a partir de
la original por eliminación de la tendencia se denominan “series de residuos”
y deberán contener predominantemente fluctuaciones estacionales. Para estimar la estacionalidad se
requiere haber decidido el modelo a utilizar (mixto o aditivo), lamentablemente
esto no es siempre claro, ya sea porque no contamos con información a priori
para suponerlo o porque el gráfico no ha dejado evidencia suficientemente clara
como para decidirnos por alguno de ellos.
En tal situación se propone calcular ambas series residuales y elegir
aquella cuyos valores correspondientes a una estación dada oscilen menos en
torno a su promedio.
Para fijar ideas, supongamos una
serie con datos trimestrales y que la información de las series residuales
pueden ser resumidas como en las tablas 2.4 y 2.5.
Tabla 2.4. Residuos modelo Mixto
|
Período |
1 |
2 |
K |
Promedio |
STD |
C.V. |
|
Estación |
|
|
|
Fila |
Fila |
Fila |
|
1 |
W(1) |
W(5) |
W(4k-3) |
|
S1 |
|
|
2 |
W(2) |
W(6) |
W(4k-2) |
|
S2 |
|
|
3 |
W(3) |
W(7) |
W(4k-1) |
|
S3 |
|
|
4 |
W(4) |
W(8) |
W(4k) |
|
S4 |
|
Tabla 2.5. Residuos modelo Aditivo
|
Período |
1 |
2 |
K |
Promedio |
STD |
C.V. |
|
Estación |
|
|
|
Fila |
Fila |
Fila |
|
1 |
R(1) |
R(5) |
R(4k-3) |
|
S1 |
|
|
2 |
R(2) |
R(6) |
R(4k-2) |
|
S2 |
|
|
3 |
R(3) |
R(7) |
R(4k-1) |
|
S3 |
|
|
4 |
R(4) |
R(8) |
R(4k) |
|
S4 |
|
Una forma de seleccionar el modelo,
es por inspección de los coeficientes de variación (C.V.). Suponemos, que en aquellas filas donde
la variación sea menor en torno a la media tendrá menor coeficiente de
variación en términos absolutos.
Luego, comparando dichos coeficientes parece razonable seleccionar el
modelo cuyos coeficientes sean menores en términos absolutos. Esto puede complementarse con gráficos
para cada fila en ambos modelos.
Finalmente, una vez que se ha
elegido el modelo a utilizar, se procede a estimar la estacionalidad.
Si el modelo es Mixto, entonces,
![]()
![]()
![]()
![]()
donde: ![]()
y si el modelo es Aditivo, entonces,
![]()
![]()
![]()
![]()
donde ![]()
Probablemente, la primera idea para
estimar la estacionalidad consistiría de los promedios por estación en las
series residuales. La corrección
que aparece arriba para cada caso, apunta a garantizar que,
![]()
![]()
como es de esperarse en el modelo teórico.
Ejemplo 3. Continuando con el ejemplo 2, tenemos lo siguiente:
Se supuso que el Modelo es Mixto ![]() y se obtuvo la serie suavizada
y se obtuvo la serie suavizada
Z(t):
|
Trimestre |
1965 |
1966 |
1967 |
1968 |
1969 |
1970 |
1971 |
|
1 |
371 |
338 |
286,5 |
373,125 |
395,25 |
342,375 |
470,625 |
|
2 |
369 |
308,375 |
314,25 |
382,25 |
382,875 |
355,875 |
506,625 |
|
3 |
367 |
284,5 |
340,5 |
391 |
366 |
382,375 |
536,375 |
|
4 |
359 |
276,25 |
359,25 |
397,75 |
348,375 |
423,625 |
558,625 |
Sea ![]() la estimación de
la tendencia (
la estimación de
la tendencia (![]() )
)
|
1965 |
1966 |
1967 |
1968 |
1969 |
1970 |
1971 |
|
|
1 |
368,83 |
337,50 |
325,19 |
331,90 |
357,63 |
402,39 |
466,16 |
|
2 |
359,21 |
332,64 |
325,09 |
336,55 |
367,04 |
416,55 |
485,08 |
|
3 |
350,78 |
328,97 |
326,48 |
342,39 |
377,63 |
431,90 |
505,18 |
|
4 |
343,55 |
326,48 |
328,44 |
349,42 |
389,42 |
448,44 |
526,47 |
Entonces, ![]() ,
donde X(t) es la serie observada.
,
donde X(t) es la serie observada.
|
Trimestre |
1965 |
1966 |
1967 |
1968 |
1969 |
1970 |
1971 |
|
|
1 |
0,77 |
0,81 |
0,67 |
0,9 |
0,94 |
0,66 |
0,83 |
0,80 |
|
2 |
1,26 |
1,18 |
1,18 |
1,34 |
1,28 |
0,96 |
1,25 |
1,21 |
|
3 |
1,12 |
0,88 |
1,17 |
1,24 |
1,02 |
0,94 |
1,15 |
1,07 |
|
4 |
1 |
0,64 |
1,04 |
1,06 |
0,79 |
0,88 |
0,97 |
0,91 |
|
|
|
|
|
|
|
|
|
0,9975 |
![]() = promedio de W(t)
para el trimestre h, h = 1, 2, 3, 4.
= promedio de W(t)
para el trimestre h, h = 1, 2, 3, 4.
 y
y 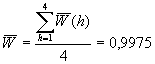
Como se observa en la siguiente
figura, en el modelo mixto estos valores varían entorno al uno.
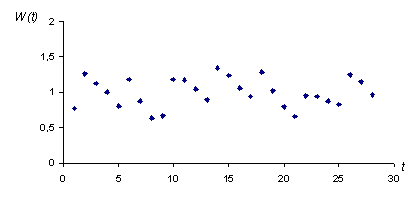
Si el modelo es Mixto, entonces,
![]() = 0,8 – (0,9975 - 1) = 0,8025
= 0,8 – (0,9975 - 1) = 0,8025
![]() = 1,21 – (0,9975
– 1) = 1,2125
= 1,21 – (0,9975
– 1) = 1,2125
![]() = 1,07 – (0,9975
– 1) = 1,0725
= 1,07 – (0,9975
– 1) = 1,0725
![]() = 0,91 – (0,9975
– 1) = 0,9125
= 0,91 – (0,9975
– 1) = 0,9125
La idea es que ![]()
En definitiva, la estimación de la
estacionalidad es,
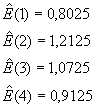
3. PREDICCIONES
Predecir, es estimar el futuro
utilizando información del presente y del pasado. El conocimiento del futuro nos capacita para planificar,
prever o prevenir.
La idea es estimar X(t) en un instante n + k posterior al último dato observado en t =n, k =
1,2,3,4,... (trimestre, mes, etc.).
Una vez estimada la tendencia y la
estacionalidad las fórmulas de predicción quedarán determinadas por:
![]() Modelo Mixto
Modelo Mixto
![]() Modelo Aditivo
Modelo Aditivo
3.1 EJEMPLO ILUSTRATIVO
Con el objeto de ilustrar los
métodos revisados en este capítulo considere los siguientes datos:
Tabla 3.1. Serie Original
|
Sem/Año |
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
1,73757 |
2,42106 |
4,47481 |
4,78939 |
5,19210 |
5,10775 |
|
2 |
2,01815 |
2,80325 |
4,85566 |
5,14076 |
5,06387 |
5,24787 |
Con el fin de eliminar los efectos irregulares y estacionalidad se obtiene la serie suavizada Z(t) con un promedio móvil centrado de orden 2, como se muestra en la tabla 3.2.
Tabla 3.2. Serie Suavizada (Z(t))
|
Sem/Año |
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
- |
2,41589 |
4,15214 |
4,89381 |
5,14721 |
5,12181 |
|
2 |
2,04874 |
3,1256 |
4,74389 |
5,06576 |
5,1069 |
- |
Una vez suavizada la serie, se
obtienen las series residuales con el objeto de eliminar la estacionalidad
dentro del modelo y saber por medio de un análisis tabular de los residuos si
el modelo es aditivo o mixto.
PRIMER CASO: Modelo Mixto. X(t) = T(t) · E(t) + A(t)
Con el objeto de eliminar la
estacionalidad de la serie, se genera la
serie de residuos:
![]()
La siguiente tabla contiene los
residuos.
Tabla 3.3. Serie de Residuos (W(t))
|
1 |
2 |
3 |
4 |
5 |
6 |
|
Sw |
CV |
|
|
1 |
- |
1,00214 |
1,07771 |
0,97866 |
1,00872 |
0,9953 |
1,01251 |
0,03813 |
0,02766 |
|
2 |
0,98507 |
0,89687 |
1,02356 |
1,0148 |
0,99157 |
- |
0,98237 |
0,05037 |
0,05127 |
La estimación de la estacionalidad para
este caso queda dada por:
![]()
![]()
![]() = 1,01251– (0,99744- 1) = 1,01251 + 0,00256 = 1,01507
= 1,01251– (0,99744- 1) = 1,01251 + 0,00256 = 1,01507
![]() = 0,98237 + 0,00256 = 0,98493
= 0,98237 + 0,00256 = 0,98493
SEGUNDO CASO: Modelo Aditivo. X(t) = T(t) + E(t) + A(t)
Como en el caso anterior y con el
objeto de eliminar la estacionalidad se construye la serie de residuos.
R(t) = X(t) - Z(t)
Los resultados se muestran en Tabla
3.4.
Tabla 3.4. Serie de Residuos (R(t))
|
1 |
2 |
3 |
4 |
5 |
6 |
|
SR |
CV |
|
|
1 |
- |
0,00517 |
0,32267 |
-0,10442 |
0,04489 |
-0,02406 |
0,04885 |
0,16256 |
3,3278 |
|
2 |
-0,03059 |
0,32235 |
0,11177 |
0,075 |
-0,04303 |
- |
-0,04184 |
0,17034 |
-4,0712 |
La estimación de la estacionalidad
para este caso queda dada por:
![]() = 0,04885 -
0,0351 = 0,04534
= 0,04885 -
0,0351 = 0,04534
![]() = 0,004184 - 0,00351 = 0,04534
= 0,004184 - 0,00351 = 0,04534
El cálculo de las series residuales
se realizó con el objeto de identificar a través de los coeficientes de
variación para cada fila de los modelos; aquel modelo que sus filas presenten
una menor variabilidad relativa a su media, será escogido como el que
interpreta a la serie a analizar.
En este caso el modelo adoptado, es el modelo mixto.
A través de este modelo se obtendrán
las proyecciones deseadas para los próximos dos semestres. Para tal efecto resta entonces obtener
una estimación de la tendencia.
Con tal fin, se ajustará una curva a la serie suavizada.
Z(t) = a + bt
Al ajustar la recta por mínimos
cuadrados se obtiene:
![]()
Yt = 0,442966 + 0,938027*t - 4,56E-02*t**2
Una vez obtenidas estas estimaciones
se utiliza la ecuación
![]()
para proyectar.
Proyecciones
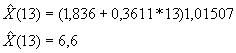
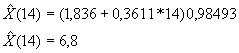
Resumen
Se llama Serie de Tiempo, a un
conjunto de mediciones de cierto fenómeno o experimento registradas
secuencialmente en el tiempo, por ejemplo a cada hora, mensualmente,
trimestralmente, semestralmente, etc..
En este apunte se trabajó con series de tiempo discreto, equiespaciadas
en cuyo caso se asume que: : {x(t1), x(t2), ..., x(tn)}=
{x(1), x(2), ..., x(n)}.
Debido al carácter introductorio se restringió al caso de series de
tiempo univariadas.
Al analizar una serie de tiempo, lo primero que se debe hacer es graficar la serie. Esto nos permite detectar las componentes esenciales de la serie. El gráfico de la serie permitirá: detectar Outlier, detectar tendencias, variación estacional, variaciones irregulares (o componente aleatoria).
Un modelo clásico para una serie de
tiempo, puede ser expresada como suma o producto de tres componentes: tendencia, estacional y un término de error
aleatorio. Existen tres
modelos de series de tiempos. Estos son:
- Aditivo: X(t) = T(t) + E(t) + A(t)
- Multiplicativo: X(t) = T(t) · E(t) · A(t)
- Mixto: X(t) = T(t) · E(t) + A(t)
Con el fin de obtener un modelo, es necesario estimar la tendencia y la estacionalidad. Para estimar la tendencia, se supone que la componente estacional no está presente. La estimación se logra al ajustar a una función de tiempo a un polinomio o suavizamiento de la serie a través de los promedios móviles. Para estimar la estacionalidad se requiere haber decidido el modelo a utilizar (mixto o aditivo). Una vez estimada la tendencia y la estacionalidad se esta en condiciones de predecir.
Los métodos revisados en este apunte son de naturaleza descriptiva, por lo que el juicio y el conocimiento del fenómeno juegan un rol importante en la selección del modelo.
Los métodos clásicos tienen la
desventaja que se adaptan a través del tiempo, lo que implica que el proceso de
estimación debe volver a iniciarse frente al conocimiento de un nuevo dato.
Bibliografía
[1] Chao, Lincoln L. (1975) Estadística para ciencias sociales y administrativas. Bogota: McGraw-Hill.
[2] Iglesias Z. Pilar. (1988). Elementos
de series de tiempo.
[3] Makridakis, S; Wheelright, S.C.; McGee, V.E. (1983). Forecasting: Methods and Applications. Wiley, New York.
[4] Peña, Daniel. (1989). Estadística,
Modelos y Métodos 2. Modelos Lineales y Series Temporales. Alianza
Universidad, Madrid.
Enlaces
- Einsteinnet (2001). Análisis Clásico De Series
Temporales. [en línea].
Disponible en: http://www.einsteinnet.com/econometria/seriestemp/acseriestemp.htm Conectado el 25 de junio de 2001.
- INEI.(2001). Desestacionalización de series de tiempo económicas.
[en línea]. Disponible
en: www.inei.gob.pe/cpi/bancopub/libfree/LIB408/LIB408.htm
Conectado el 26 de junio de 2001.