La siguiente técnica que vamos a presentar son las ecuaciones estructurales, Structural Equation Model (SEM). SEM supone una segunda generacion de análisis multivariante (Fornell, 1987) que toma lo mejor de técnicas de reducción de datos como el Análisis de Componentes Principales y técnicas que estudian la relación entre las variables, como la Regresión Multivariante.
SEM permite modelizar complejas relaciones entre variables observables y variables latentes de manera precisa. Esta técnica se ha utilizado generalmente para analizar encuestas pero tiene mucho potencial para analizar la información financiera.
 Artículo
para leer: Wynne W. Chin (1998): Issues and Opinion on Structural Equation Modeling,
Management Information Systems Quarterly, Volume 22, Number 1. Artículo
para leer: Wynne W. Chin (1998): Issues and Opinion on Structural Equation Modeling,
Management Information Systems Quarterly, Volume 22, Number 1. |
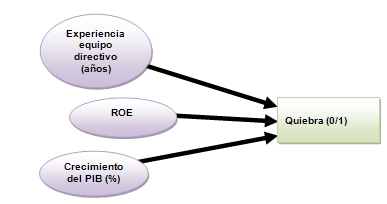
El gráfico muestra un modelo para predecir la quiebra de una empresa, en el que hemos determinado una variable dependiente (la quiebra, 0/1) y varios factores explicativos, que se corresponden con tres variables observables. A partir de ahí podríamos aplicar un modelo de regresión multivariante y realizar el correspondiente contraste.
El siguiente gráfico muestra un modelo de ecuaciones estructurales.
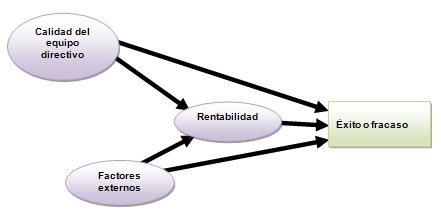
Dos son las diferencias: la complejidad de las relaciones (con efectos directos e indirectos) y la posibilidad de incorporar variables latentes o constructos, es decir, variables no observables directamente. Por ejemplo, un intangible como la "calidad del equipo directivo".
En las ecuaciones estructurales se puede trabajar con estas variables latentes. Ahí interviene el análisis de componentes principales.
|
Una solución es hacer como se viene haciendo desde hace muchos años con el constructo "inteligencia". Se proponen un conjunto de indicadores relacionados con dicho constructo y que sí que se pueden medir, como la memoria o la capacidad de cálculo. Se comprueba que dichos indicadores está relacionados entre sí, con una serie de medidas de consistencia interna que veremos a continuación. Así funcionan los "test de inteligencia".
|
 Hay que mirar con lupa
la correlación Hay que mirar con lupa
la correlación
La correlación es una medida que indica la fuerza y dirección de una relación entre dos variables. Existe correlación entre A y B si al aumentar los valores de A lo hacen también los de B y viceversa. Hay varios coeficientes de correlación, uno de los más usados es el coeficiente de correlación de Pearson, que se obtiene dividiendo la covarianza de dos variables por el producto de sus desviaciones estándar. El valor del coeficiente oscila entre -1 y +1. En el SPSS está en [Analizar] [Correlaciones] [Bivariadas]
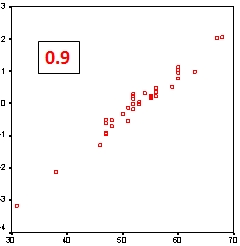 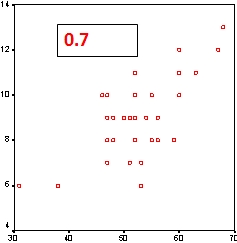 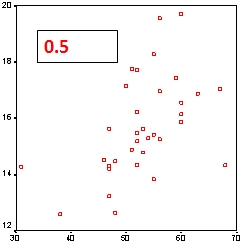
Conviene mirar también el otro coeficiente de correlación, el de Spearman, muy apropiado cuando hay valores extremos, ya que esos valores extremos pueden alterar el valor del coeficiente de Pearson. En el de Spearman los datos son reemplazados por su respectivo orden. Es decir que si tenemos la población de varias ciudades (Sevilla, 703.206; Madrid, 3.255.944; Barcelona, 1.621.537; Valencia, 814.208; y Zaragoza, 674.317) lo que hace es reemplazar el número de habitantes por su orden, es decir (Sevilla, 4; Madrid, 1; Barcelona, 2; Valencia, 3; y Zaragoza, 5). |
Una utilidad de las ecuaciones estructurales es que sirven para estimar los llamados "modelos causales". Esto ya son palabras mayores porque es muy difícil establecer una relación causal. Recordemos la frase del filósofo griego Democrito (el de los átomos) que dijo aquello de que "Preferiría descubrir una ley causal que ser rey de Persia".
Algo elemental para empezar es recordar que "Correlación no significa causalidad". Dos falacias clásicas lo explican muy claramente, "Cum_hoc_ergo_propter_hoc" (con esto, luego a causa de esto) y "post hoc ergo prompter hoc" (después de esto, por lo tanto, a consecuencia de esto). Es típico en la falsa medicina: cuando tengo gripe, tomo zumo de arándanos y los siete días se me cura..
Hay que evitar cometer los errores habituales en los estudios mal realizados que detectan correlación entre A y B y de ahí extraen la conclusión precipitada de que A->B.
Pero:
- 1) Puede ser que B->A. [Donde hay más ONG hay más conflictos... ¡pero las ONG no son la causa sino que van a ayudar allí donde hay lío!: Debate ONGs y conflictos]
- 2) Puede que sea mera casualidad. [lluvia acumulada y crecimiento población]
- 3) Puede que A-> B y B-> A. [presión y temperatura]
- 4) A->b pero irrelevante. Fumar causa el calentamiento global del planeta.
- 5) Puede que haya un tercero C que sea la causa de A y de B. Correlación espuria.
|
|
Hay varias etapas que en lo básico coinciden con lo que se denomina el método científico o ciclo de la investigación científica. Nosotros vamos a detallar estas fases:
- Unidimensionalidad
- Fiabilidad
- Validez convergente
- Validez discriminante
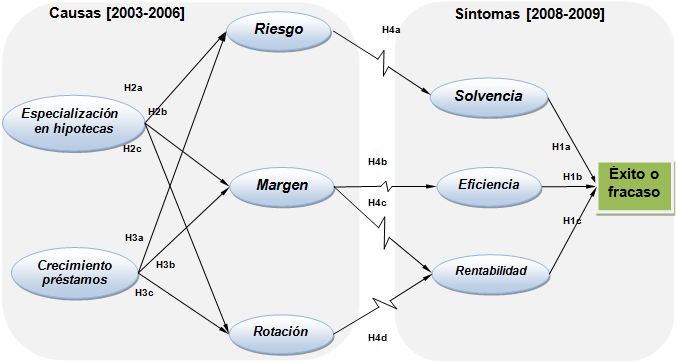
Modelizar es representar una realidad compleja. Un dibujo, que en este contexto se llama diagrama estructural, puede ser muy útil. Veamos un ejemplo de los factores que conducen a las empresas a la quiebra según Ooghe y Waeyaert (2004).
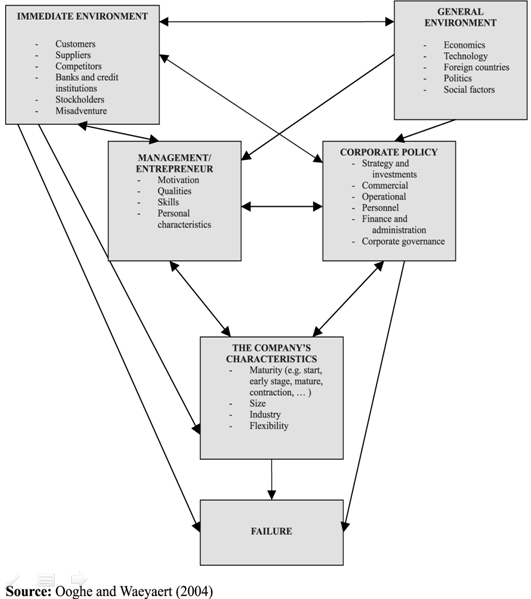
|
Ejercicio: Realice diagramas causales según las teorías expuestas por los autores anteriores. |
Veamos otros ejemplos.
En este caso se trata de explicar de qué depende el que un ayuntamiento tenga un buen servicio de gobierno electrónico. Igual que para una buena singladura es necesario un un buen barco, el mejor capitán y viento favorable, en nuestra opinión hacen falta tres cosas: dinero (un ayuntamiento con recursos), ganas (un alcalde al que le gusten las tecnologías) y un entorno favorable (empresas y ciudadanos con nivel tecnológico).
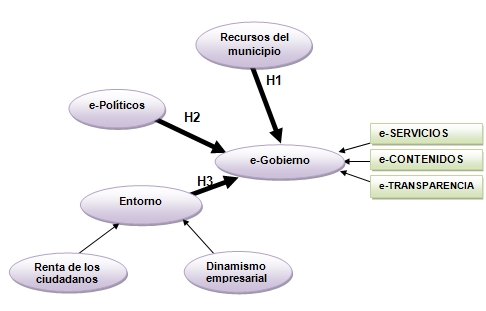
- Serrano-Cinca, C.; Rueda, M. and Portillo, P. (2009): "Determinants of e-government extension: a structural equation model", Online Information Review, Vol 33 (3), pp 476 - 498
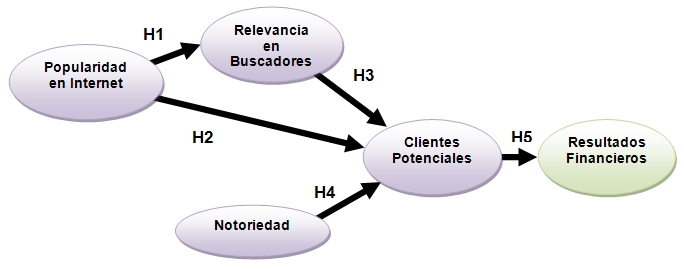
En este otro caso tratábamos de buscar factores que explicaran el éxito de las empresas que venden por Internet. Para que una empresa venda por Internet necesita muchas visitas a su web, pues esos visitantes son clientes potenciales. Y para eso hace falta estar bien posicionado en los buscadores y también presencia en las redes sociales, como blogs. Un factor para conseguir estar bien posicionado en Internet es ser popular en Internet, lo que se consigue teniendo muchos enlaces (links) a la web. Además eso atrae más publico a la web.
|
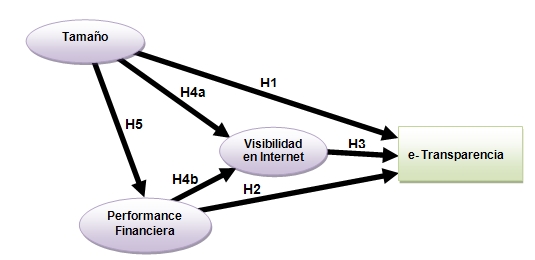
En este otro trabajo hemos modelizado los factores que explican que los bancos divulguen sus cuentas anuales en Internet, es decir sean transparentes. Pensamos que un factor es el tamaño, otro la visibilidad en Internet (aquellas que sean muy populares y tengan banca electrónica poderosa) y finalmente si lo hacen bien en términos de rentabilidad, solvencia, etc.
|
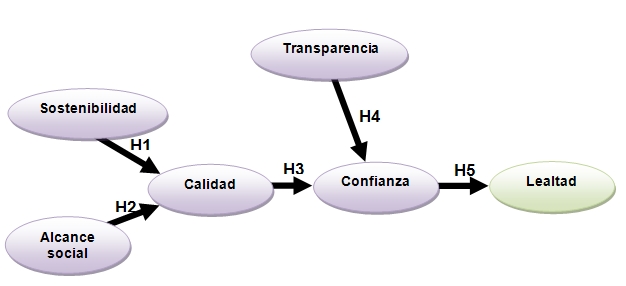
En este otro trabajo desarrollamos una cadena explicativa de la lealtad de los donantes que financian a las entidades que conceden microcréditos. Como antecesor de la lealtad proponemos la confianza, y pagar ganar confianza es importante ser transparente y hacer las cosas bien, tanto en los aspecto financieros como en los sociales. Este trabajo se hizo con una encuesta a donantes.
|
A continuación se definen las variables latentes o constructos. Por ejemplo, el constructo "recursos del municipio", trata de capturar las características propias del ayuntamiento, como su tamaño, fortaleza económica o capacidad tecnológica.
El constructo "e-transparencia" representa el nivel de divulgación de información contable en Internet. Podemos suscribir la definición de Bushman et al (2004), "corporate transparency is defined as the widespread availability of firm-specific information to those outside the firm", puntualizando que nos referimos a la disponibilidad en Internet.
El constructo "tamaño de la entidad", aunque a priori parece una variable medible lo cierto es que no tiene una única definición y hay numerosas variables que se relacionan con el tamaño, desde el número de empleados a la cifra de ventas, activos, empleados o valor en bolsa. Es decir, la cifa de ventas es un indicador pero el "tamaño" es un constructo.
En la siguiente fase se proporcionan argumentos teóricos que sustentan las hipótesis. Este apartado es fundamental, ya que el tipo de resultado al que se aspira no es una mera relación estadísticamente significativa sino una relación causal.
|
Nótese la diferencia entre:
|
Veamos un ejemplo de como se suele redactar la hipótesis sobre la relación entre la "relevancia en buscadores" y su efecto en los "clientes potenciales":
De acuerdo con el estudio de Nielsen Netratings (2004) sobre comportamiento de los internautas, el 76% de los internautas de EEUU utiliza los buscadores, que continúan siendo la herramienta más utilizada para navegar por la web. Como tendencia destaca que los compradores online acuden a los buscadores no solo para localizar las tiendas sino para realizar comparaciones de productos. En el estudio conjunto realizado por ComScore Networks y DoubleClick (2005) se monitoriza la utilización que hacen los usuarios durante 12 semanas antes de la compra online. El estudio revela que más del 50% de las decisiones de compra empiezan en los buscadores, destacando el elevado número de consultas realizadas varias semanas antes de la compra.
Para Drèze y Zufryden (2004) la visibilidad en Internet -medida según el posicionamiento en buscadores, directorios y otras fuentes- es el precursor del tráfico a la web. En su estudio se construye un índice de visibilidad y se contrastan varias hipótesis, incorporando preguntas de un cuestionario telefónico realizado a 100 empresas de Internet. La visibilidad online se relaciona con el tráfico a la web y es capaz de predecirlo. Se muestra que tiene más impacto significativo para generar tráfico que los gastos en publicidad o el conocimiento de marca.
Expuesta la importancia de los buscadores para generar tráfico, las empresas que venden productos por Internet precisan que esté bien posicionada en buscadores, es decir, que cuando un internauta ponga una palabra clave relacionada con los productos que comercializa la empresa, aparezca la web en las primeras posiciones del buscador. Por ejemplo, para una librería online es importante que al poner una palabra clave como "libros", o el título del libro solicitado aparezca en las primeras posiciones del buscador la tienda virtual. Para determinar la posición que ocupa en los resultados de la búsqueda, los buscadores utilizan algoritmos. Dichos algoritmos son los responsables de determinar la "relevancia en el buscador". Un ejemplo es el algoritmo PageRankTm, verdadero corazón del buscador Google, véase Brin y Page (1998).
Por ello podemos plantear la siguiente hipótesis:
Hipótesis 2a.
La "relevancia en buscadores" tiene un efecto positivo en los "clientes potenciales".Otro ejemplo:
Se plantea como primera hipótesis que son las entidades financieras más grandes las que tienden a revelar información financiera en Internet. La teoría de la red contractual sustenta esta hipótesis pues las compañías de mayor tamaño tienen mayores problemas de asimetría de información entre gestores y accionistas, lo que conlleva a su vez unos elevados costes de agencia. Como señalan Firth (1979) y Chow and Wong-Boren (1987), la solución a este problema vendría a través de una mayor difusión de información por parte de las empresas grandes que las de menor tamaño. También la teoría del coste político, Watts and Zimmerman (1986), sustenta esta hipótesis al sostener que las organizaciones mas grandes estarían motivadas hacia una mayor divulgación de información en respuesta a presiones políticas. La relación positiva entre revelación de información, tanto voluntaria como obligatoria, y el tamaño ha sido contrastada empíricamente en numerosos estudios (Cerf, 1961; Singhvi and Desai, 1971; Stanga, 1974; Buzby, 1975; Belkaoui and Kahl, 1978; Firth, 1979; Courtis, 1979; McNally et al., 1982; Cooke, 1989a, 1989b, 1992; Wallace et al., 1994; Giner, 1997). De acuerdo con Ahmed and Courtis (1999) y Larrán and Giner (2002) el tamaño es la variable que en mayor número de estudios de divulgación sale significativa.
En resumen, son muchos los argumentos que justifican que cuanto más grandes son las empresas más y mejor información financiera publican. Por ello, planteamos la siguiente hipótesis:
H1: El "tamaño de la entidad" tiene un efecto positivo en la "e-transparencia", en las entidades de crédito.
Ya se ha planteado el modelo desde un punto de vista teórico. Ahora toca contrastarlo. En primer lugar se presentan los datos disponibles y sus limitaciones.
A continuación se identifican los indicadores (variables observables, medibles) para cada constructo.
Una distinción importante es entre indicadores reflectivos y formativos. Los indicadores reflectivos reflejan el constructo (son un síntoma del constructo, causados por el constructo) mientras que los formativos son la causa del constructo. Lo vemos con un ejemplo, el constructo "borracho".
Constructo [no se puede medir] Indicadores reflectivos [sí se pueden medir y están correlacionados] Indicadores formativos [sí se pueden medir y no está correlacionados]
- Borracho
- Nivel de alcohol en sangre
- Hacer eses
- Vomitar
- ...
- Copas de vino bebidas
- Jarras de cerveza
- Chupitos de whisky
- ...
Nótese en el gráfico como se representan de forma diferente ambos tipos de indicadores, según el sentido de las flechas "constructo-> se refleja en" "indicadores forman -> el constructo".
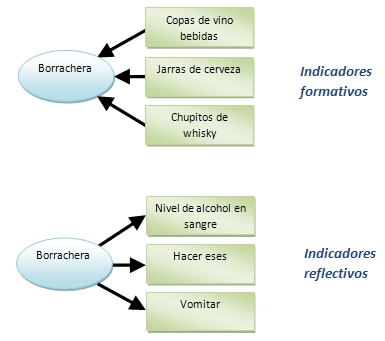
Una forma de distinguir si los indicadores son reflectivos o formativos es mediante la correlación. Los reflectivos sí que están correlacionados entre sí: un borracho tiene alcohol en la sangre, hace eses, vomita... cuanto más alcohol tiene en la sangre más vomita y más eses hace. En los indicadores formativos, en cambio, no hay correlación entre ellos. Por ejemplo si uno bebe más vino no necesariamente aumenta la cantidad de cerveza que bebe o de whisky. En los ejemplos anteriores, indicadores de "tamaño" pueden ser la cifra de ventas, el número de empleados o la cotización bursátil. O de "rentabilidad" el ROA y el ROE. En general se suelen utilizar indicadores reflectivos.
|
|
El modelo de medida contempla las relaciones entre cada constructo y sus indicadores y se basa en el cálculo de los componentes principales. Aunque la técnica de extraer los componentes principales es muy utilizada en la investigación contable como técnica de análisis exploratorio, la forma de operar en ecuaciones estructurales es diferente. Se utiliza un procedimiento deductivo: el investigador propone a priori los indicadores que han de formar el constructo y se van descartando aquellos que no cumplen ciertas propiedades de consistencia interna como unidimensionalidad, fiabilidad, validez convergente y validez discriminante.
Unidimensionalidad
En primer lugar se comprueba que los indicadores que integran cada constructo son unidimensionales. Se realiza un análisis de componentes principales para cada constructo y se aplica el criterio de Kaiser (1960), es decir que solo para el primer componente principal el valor propio es mayor que 1. Jolliffe (1972) sugiere un valor de 0.8. Se realizan tantos análisis de componentes principales como constructos. Otro dato relevante es el porcentaje de varianza explicada. En este caso se espera que el primer componente explique la mayor parte de la varianza.
Fiabilidad
La fiabilidad (reliability) mide la consistencia de los indicadores que forman el constructo, es decir, que los indicadores están midiendo lo mismo. Se calcula el alpha de Cronbach, Cronbach (1970), y el la fiabilidad compuesta (composite reliability), Werts et al. (1974), que oscilan entre 0 (ausencia de homogeneidad) y 1 (máxima homogeneidad). La diferencias es que el alpha de Cronbach presupone a priori que cada indicador de un constructo contribuye de la misma forma mientras que la fiabilidad compuesta utiliza las cargas de los ítems tal como existen en el modelo causal. Lo más habitual es considerar como criterio de fiabilidad que los valores de ambos índices sean superiores a 0.8. Una escala es fiable si los ítems estén muy correlacionados entre sí. Para calcular el alfa de Cronbach se aplica la siguiente fórmula.

|
|
En el caso de los indicadores formativos no tiene sentido calcular la unidimensionalidad ni la fiabilidad. En este caso lo que se analiza es la multicolinealidad. Un criterio para detectar la presencia de multicolinealidad es el VIF (Variance inflation factor). De acuerdo con Belsley et al (1980) existe multicolinealidad severa si el VIF es mayor que 10. Kleinbaum et al (1988) rebajan el umbral de VIF a 5.
Validez convergente
La fiabilidad es un criterio de consistencia, pero no es el único que debe cumplirse. En el caso del examen imagina que se han seleccionado 3 preguntas muy fiables... pero que no tienen nada que ver con el temario. El alfa de Cronbach sería elevada pero las tres preguntas no serían válidas. Por tanto, otra medida que debe estudiarse es la validez. Lo vemos en el siguiente gráfico.
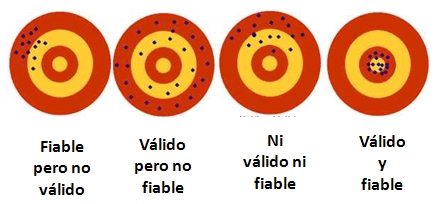
Se habla de validez de contenido, validez convergente y validez discriminante. Para establecer la validez de contenido se revisa la literatura y se trata con expertos en la materia.
La validez convergente "is the degree to which the indicators reflect the construct, that is, whether it measures what it purports to measure". Se ha calculado el Average Variance Extracted (AVE) que mide que la varianza del constructo se pueda explicar a través de los indicadores elegidos, Fornell y Larcker (1981). Los valores mínimos recomendados son 0.5, Baggozi y Yi (1998), lo que quiere decir que más del 50% de la varianza del constructo es debida a sus indicadores.
Para calcular el AVE se realiza un análisis de componentes principales. Después se toman las cargas factoriales y para cada uno de ellos se calcula el cuadrado. Las cargas factoriales las da el SPSS que en realidad son el coeficiente de correlación entre el indicador y el valor del componente principal. Luego 1 menos ese cuadrado y una serie de operaciones. Aquí hay una excel [AVE.xls] que ayuda a calcularlo, aunque el programa PLS Graph también lo proporciona. Esa misma excel también calcula la fiabilidad compuesta.
El segundo criterio para analizar el cumplimiento de la validez convergente es comprobar que las cargas factoriales de la matriz de componentes principales sean >0.5 para cada uno de los indicadores, Jöreskog y Sörbom (1993) o 0.70 para Chin (1998).
Validez discriminante
La validez discriminante implica que cada constructo debe ser significativamente diferente del resto de los constructos con los que no se encuentra relacionado según la teoría. Para analizar la validez discriminante se obtuvo la matriz de cargas factoriales y cargas factoriales cruzadas. Las cargas factoriales son coeficientes de correlación de Pearson entre los indicadores y su propio constructo. Las cargas factoriales cruzadas son coeficientes de correlación de Pearson entre los indicadores y los otros constructos. Las cargas factoriales debe ser mayores que las cargas factoriales cruzadas. Es decir, los indicadores deben estar más correlacionados con su propio constructo que con los otros.
El segundo criterio para verificar la validez discriminante es que la raíz cuadrada del AVE del constructo sea mayor que la correlación entre ese constructo y todos los demás, Chin (1998). La tabla 6 muestra los coeficientes de correlación entre los constructos. Nótese que en las diagonales en vez del clásico valor de 1, se ha de mostrar la raíz cuadrada del AVE. Además, para Bagozzi (1994) las correlaciones entre los distintos factores que componen el modelo no deben ser superiores a 0.8
Testar el cumplimiento de las propiedades que aseguran la internal consistency es importante. Ahora podemos hablar con propiedad de "tamaño", "transparencia", "rentabilidad", etc y establecer relaciones entre dichas variables latentes. Es una aportación frente a los estudios que manejan variables observables, en los que los investigadores deben limitarse a plantear hipótesis entre variables como Activo Total y ROE, siendo los resultados menos generales.
Hay dos formas de estimar las ecuaciones estructurales, los métodos basados en el análisis de las covarianzas, mediante programas estadísticos tales como LISREL, EQS, AMOS, y los basados en análisis de componentes principales o Partial Least Squares. Nosotros preferimos con información financiera el uso de Partial Least Squares (PLS) porque se orienta al análisis causal predictivo y los resultados se interpretan comos los de una regresión, con R2 y betas.
Los parámetros se estiman con un procedimiento bootstrap con varios cientos de iteraciones. Los coeficientes de regresión estandarizados beta llamados "path coefficients" en la jerga de SEM, los valores de la t de student y los R2 (R-square).
Los R-square miden la cantidad de varianza del constructo que es explicada por el modelo.
Los coeficientes path estandarizados permiten analizar el cumplimiento de las hipótesis planteadas. Chin (1998) sugiere que para ser considerados significativos, deberían situarse por encima de 0.3.
La fase última correspone a la interpretación de los resultados. Se deben justificar las hipótesis que no se cumplen, proponer modelos alternativos, etc.
Veamos en la siguiente página un ejemplo de aplicación de las ecuaciones estructurales.
 Variables latentes
e indicadores
Variables latentes
e indicadores  Modelizar los factores
que causan quiebras empresariales
Modelizar los factores
que causan quiebras empresariales