|
Inteligencia Artificial |
Manual de uso del programa Teruel, una red neuronal autoorganizada |
Citar
como: Medrano,
N y
Martín,
B (2001): "Manual de uso del programa Teruel, una red neuronal
autoorganizada", [en línea] 5campus.com, Inteligencia Artificial
<http://www.5campus.com/leccion/teruel> [y añadir fecha consulta]
El programa Teruel, desarrollado en el Departamento de
Ingeniería Electrónica y Comunicaciones de la Universidad de Zaragoza, ha sido
diseñado para la simulación de redes neuronales de tipo competitivo y con
aprendizaje no supervisado denominadas Mapas autoorganizados o redes de
Kohonen.
Recomendamos la lectura del libro
escrito por Bonifacio Martín del Brío y Alfredo Sanz. "Redes Neuronales y Sistemas Borrosos. Introducción Teórica
y Práctica", Editorial RA-MA, Madrid, 1997.
La función de similitud
empleada es la definida por la distancia de Manhattan:
![]()
El decaimiento de los
parámetros del proceso de entrenamiento, ritmo de aprendizaje () y radio de vecindad () es de tipo lineal,
definido como
![]()
![]()
|
|
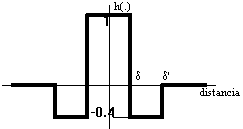
La función vecindad viene dada por una
función de "sombrero mejicano" linealizada a tramos, como se indica
en la figura.
Los valores límites (máximo y mínimo) de los
diferentes parámetros se hallan especificados en la tabla adjunta.
Los datos (patrones de
entrada y pesos) son suministrados al programa a través de ficheros. Los correspondientes a la configuración de
un mapa ya existente (es decir, los pesos de la red, dimensiones X e Y, etc.)
son elaborados por el propio programa, dándoles por defecto extensión *.w (de "weights", pesos en
inglés); los ficheros que contienen la información sensorial (por defecto, con
extensión *.in, de
"inputs", entradas en inglés), los patrones de entrada, deben ser
elaborados previamente. Todo fichero de
entradas debe tener un aspecto similar al siguiente:
2 2 4
1 0 0 0 0
0 1 0 0 1
0 0 1 0 2
0 0 0 1 3
En la primera línea debe
aparecer la información correspondiente al número de componentes de los
patrones y al número total de patrones incluidos en el fichero. El número de componentes de cada vector viene
dado por el producto de los dos primeros números, en el ejemplo 2x2 = 4
componentes (suponemos vectores de entrada de dos dimensiones). El siguiente número de la primera línea
indica el número de patrones contenidos en el fichero. En este caso, 4.
Cada una de las siguientes
líneas está asociada a cada uno de los patrones. Dado que en la línea inicial se indica que hay 4 patrones, el
número de líneas posterior será 4. En
caso de haber más, serán ignoradas.
En las líneas
correspondientes a patrones debe haber tantas columnas (números) como
componentes tiene el patrón más uno. Si
los vectores de entrada tienen, según indique la línea inicial, N componentes,
las N primeras columnas de la fila asociada a un patrón corresponderán a
aquellas. La siguiente columna, la
última, es una etiqueta que, si bien la red neuronal no emplea para su
entrenamiento, el programa utiliza para diferenciar patrones, asignándoles un
color y una letra diferente, facilitando así el reconocimiento de grupos en la
representación gráfica. Si en nuestros
datos desconocemos qué grupos existen, bastará con rellenar esta última columna
con ceros, teniendo presente que en la representación gráfica de los vectores
sobre la red no se mostrará nada más que un tipo de patrón. El programa es capaz de admitir hasta un
máximo de 7 tipos de patrones diferentes (la última columna de estas filas
puede tomar valores de cero a seis), asignándoles a cada uno de ellos un color
diferente y una letra distinta (de la A a la G). En nuestro ejemplo, cada uno de los 4 patrones pertenece a una
clase diferente, etiquetadas de 0 a 3.
|
PARAMETRO |
MINIMO |
MAXIMO |
|
Nº de patrones |
1 |
400 |
|
Nº de componentes de
entrada |
1x1 |
12x4 |
|
Neuronas en la dimensión X |
1 |
20 |
|
Neuronas en la dimensión Y |
1 |
20 |
|
Límite inferior de
inicialización aleatoria de pesos |
-0.99 |
0 |
|
Límite superior de
inicialización aleatoria de pesos |
0 |
0.99 |
|
Radio de vecindad |
1 |
20 |
|
Ritmo de aprendizaje |
0.01 |
0.99 |
|
Nº de iteraciones de
entrenamiento |
1 |
1000 |
|
Its. hasta hacer delta
mínimo |
1 |
1000 |
|
Its. hasta hacer epsilon
mínimo |
1 |
1000 |
|
Its. entre refrescos de
pantalla |
1 |
1000 |
|
Vista de pesos: saturación
en valores positivos |
0 |
5 |
|
Vista de pesos: saturación
en valores negativos |
-5 |
0 |
|
Discriminador en
recuerdo-actividad máxima |
0 |
1 |
|
Número de clases
diferentes visualizables (ver texto) |
1 |
7 |
|
|
El programa se encuentra representado por el
siguiente icono:
Tras activar el programa, aparecerá
la ventana de trabajo desde la que se pueden efectuar todas la opciones
disponibles.
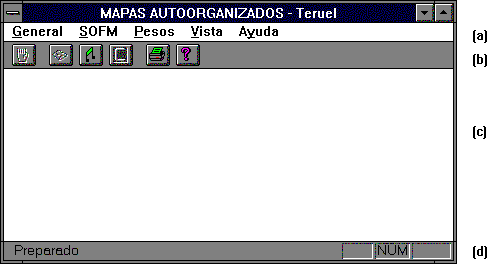
En ella pueden diferenciarse
cuatro zonas principales, que en la figura vienen indicadas como (a), (b), (c)
y (d).
(a) Corresponde a los menús desplegables. Desde aquí puede accederse a las principales
opciones del programa.
(b) Barra de herramientas. Corresponde fundamentalmente a acciones que
modifican las características de las opciones seleccionadas mediante (a), así
como un acceso rápido a selecciones que aparecen en menú desplegable.
(c) Zona de trabajo. Sobre ella se producirán los resultados de
las opciones que se vayan seleccionando (procesos de aprendizaje, recuerdo,
etc.).
(d) Línea de ayuda. Presenta una breve descripción de los
comandos que en cada momento se pueden ejecutar, con sólo situar el ratón con
su botón izquierdo presionado sobre la opción deseada.
MENUS DESPLEGABLES (zona "a" de la ventana)
Menú general
Desde esta opción del
programa podemos efectuar las acciones correspondientes a inicialización de
impresora (a través de un menú de selección que permite variar la impresora
predeterminada, orientación del papel y calidad de impresión entre otras cosas)
e impresión de la pantalla activa, con lo que en ella se muestre en ese
momento. Asimismo podemos seleccionar
el fichero de patrones de entrada o de pesos que deseemos utilizar, pudiendo
hacerlo en cualquier momento de la ejecución, siempre que sea compatible con el
correcto funcionamiento del programa.
Finalmente podemos, desde este menú, cerrar el programa con la opción Salir.
Menú SOFM
Desde este menú accedemos a
los submenús correspondientes a los procesos de recuerdo (recall) y aprendizaje (learning)
del mapa auto-organizado.
i) Proceso de recuerdo: Seleccionando
esta opción el programa nos mostrará el resultado de proyectar sobre el mapa ya
entrenado que deseemos los patrones de entrada que en ese momento estén
almacenados en memoria. El fichero de
pesos del mapa es seleccionado mediante una caja de diálogo como la siguiente:
Si el programa no tiene
almacenado en memoria ningún conjunto de patrones solicitará la carga de un
fichero de patrones mediante una caja de diálogo similar a la anterior.
En cualquiera de los casos,
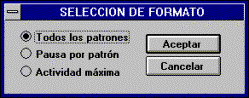
el programa presenta las tres posibilidades de recuerdo que posee: presentación de todos los patrones sobre el
mapa; presentación patrón a patrón mostrando la actividad que cada neurona
ofrece frente al vector de entrada actual, o mapa de actividades máximas.
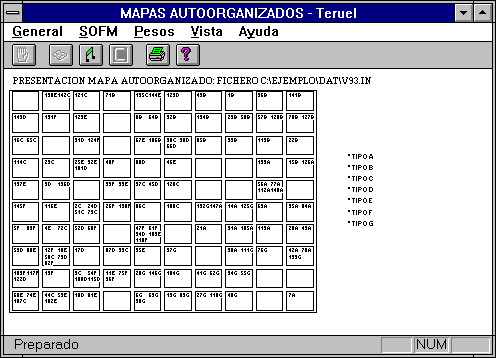
- Todos los patrones. En pantalla se mostrará la posición que cada uno de los patrones
ocupa dentro del mapa, pudiéndose observar los que se presentan próximos entre
sí, los alejados, etc. Cada patrón es
representado por un número, que indica la posición dentro del fichero de
patrones, y una letra, que indica la clase que en el fichero tiene asignada
(última columna del fichero). Además,
cada patrón presenta un color distinto según su clase.
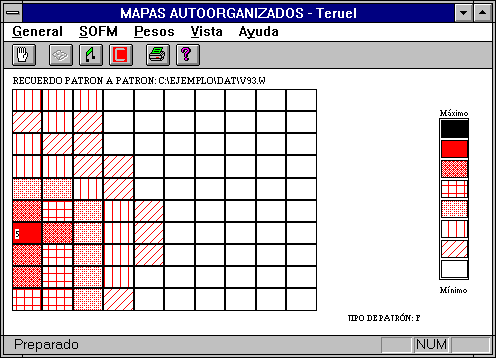
- Pausa por patrón. En pantalla se presentan uno a uno los patrones, mostrando la
actividad que cada una de las neuronas presenta frente a este mediante una
escala gradual de colores.
- Actividad máxima. Sobre cada neurona aparece el patrón o los dos patrones, (según
el factor de discriminación que indiquemos), que más activan a cada neurona.
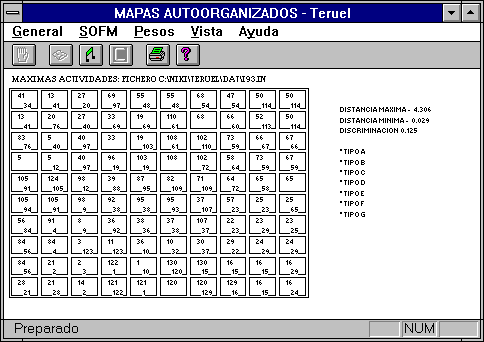
El factor de discriminación
es la diferencia máxima que deben tener las distancias de Manhattan de dos
patrones a una misma neurona para ser ambos representados en ella en esta
modalidad de recuerdo.
ii) Proceso de aprendizaje: Permite
elegir entre un aprendizaje partiendo de un mapa previamente entrenado o de un
mapa sin entrenar, cuyos pesos hayan sido inicializados aleatoriamente.
En el primer caso, y tras haber seleccionado el
fichero de pesos del que se desea partir, se procede a introducir a través de
una nueva ventana de diálogo los parámetros de aprendizaje deseados: ritmo
inicial de aprendizaje (epsilon), radio inicial de la vecindad (delta), número
de iteraciones hasta alcanzar el valor mínimo de ambos parámetros, iteraciones
hasta finalizar el entrenamiento y número de iteraciones entre dos
actualizaciones consecutivas de pantalla.
En caso de elegir el entrenamiento de un nuevo mapa,
partiendo de un conjunto de pesos aleatorio, el número de parámetros que deben
introducirse aumenta. La ventana de
diálogo permite seleccionar los valores de las dimensiones X e Y del mapa,
valores máximo y mínimo entre los que se encontrarán los pesos aleatorios
iniciales, así como los parámetros indicados en el párrafo anterior.
Conforme el proceso de aprendizaje se lleva a cabo,
en pantalla se visualiza la evolución de los parámetros de entrenamiento, , , variación máxima de los
pesos, número de iteraciones pendientes, etc.
Menú Pesos
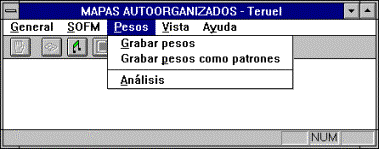
Seleccionando Grabar pesos se efectúa una grabación en
disco de los pesos de la red almacenados actualmente en memoria. Grabar
pesos como patrones almacena los pesos en el formato de los patrones de
entrada, pudiendo emplearlos como datos de aprendizaje. La opción Análisis presenta mediante una escala de colores el valor de cada
uno de los pesos asociados a cada neurona, donde el rango de rojos corresponde
a valores de pesos positivos, el rango de azules a negativos y el color blanco
representa valor próximo a cero.
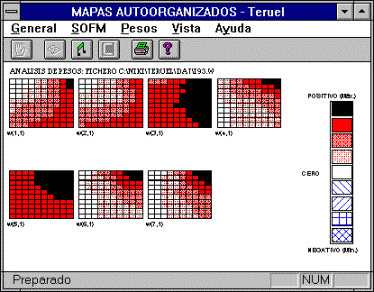
Por defecto, se representan
como valores máximo y mínimo de pesos los límites 5. Valores mayores o menores que estos límites serán representados
de igual forma ("saturación").
Si se desea saturar la representación en valores absolutos más pequeños,
basta indicarlo en la ventana de diálogo que aparece al seleccionar este
comando.
Menú Vista
Permite mostrar u ocultar la
barra de herramientas (menú de botones, campo (b)) y la barra de estado, que es
la que contiene la línea de ayuda, campo (d).
Menú Ayuda
Presenta información sobre el origen del
programa.
BARRA DE HERRAMIENTAS (zona "b" de la ventana)
Consta de un
conjunto de botones icónicos, accesibles en determinados momentos de la
ejecución del programa, que permiten modificar la actuación del programa o
acceder de forma más rápida a determinadas opciones.
![]() Parada
de ejecución. Finaliza la tarea
en curso. Este botón está activo (es
decir, se puede emplear) en los procesos de aprendizaje y en el recuerdo patrón
a patrón.
Parada
de ejecución. Finaliza la tarea
en curso. Este botón está activo (es
decir, se puede emplear) en los procesos de aprendizaje y en el recuerdo patrón
a patrón.
![]() Recuerdo. Permite ver el estado actual del mapa
auto-organizado en proceso de entrenamiento, independientemente del número de
iteraciones que se hayan producido desde la última actualización automática.
Recuerdo. Permite ver el estado actual del mapa
auto-organizado en proceso de entrenamiento, independientemente del número de
iteraciones que se hayan producido desde la última actualización automática.
![]() Activación/desactivación
de la señal sonora. Durante el
entrenamiento de un mapa, una señal sonora indica la finalización de una nueva
iteración. Esta señal sonora puede
activarse y desactivarse a voluntad, con sólo presionar este botón.
Activación/desactivación
de la señal sonora. Durante el
entrenamiento de un mapa, una señal sonora indica la finalización de una nueva
iteración. Esta señal sonora puede
activarse y desactivarse a voluntad, con sólo presionar este botón.
![]() Cambio
de parámetros/Cambio de patrón.
Accionando este botón en un proceso de aprendizaje podemos alterar los
parámetros básicos de entrenamiento: ritmo de aprendizaje, radio de vecindad,
número de iteraciones en las que se producirá el entrenamiento y en las que
decaerán los parámetros epsilon y delta, así como el número de iteraciones
entre dos refrescos de pantalla. Si el
botón es presionado durante un proceso de recuerdo patrón a patrón, en pantalla
se visualizará el siguiente al representado en ese momento en la ventana
activa.
Cambio
de parámetros/Cambio de patrón.
Accionando este botón en un proceso de aprendizaje podemos alterar los
parámetros básicos de entrenamiento: ritmo de aprendizaje, radio de vecindad,
número de iteraciones en las que se producirá el entrenamiento y en las que
decaerán los parámetros epsilon y delta, así como el número de iteraciones
entre dos refrescos de pantalla. Si el
botón es presionado durante un proceso de recuerdo patrón a patrón, en pantalla
se visualizará el siguiente al representado en ese momento en la ventana
activa.
![]() Imprimir. Similar a la opción de imprimir del menú
desplegable.
Imprimir. Similar a la opción de imprimir del menú
desplegable.
![]() Información. Similar a la opción de información del menú
desplegable.
Información. Similar a la opción de información del menú
desplegable.
Aplicación
de los mapas auto-organizados a la visualización y representación de datos.
A continuación vamos a estudiar el
comportamiento que un mapa de Kohonen presenta ante un conjunto de patrones
pertenecientes a un determinado espacio sensorial de entrada. Para familiarizarnos con el entorno,
abordaremos inicialmente un problema académico sencillo, analizando los
resultados obtenidos, para posteriormente introducirnos en el problema real: la
representación de los datos pertenecientes a la crisis bancaria española de
1977-1985.
Un
caso real: la crisis bancaria de 1977-1985. Para este apartado, haremos uso de un fichero de patrones que
contiene información económica de 66 de los bancos más importantes de esa época
[Martín y Serrano, 1992]. Cada uno de
ellos, etiquetado con un 0 o un 1 según su estado final tras el periodo de
crisis (quiebra o salud económica respectivamente), se encuentra representado por un conjunto
de parámetros económicos (en un total de 9) denominados ratios, adecuadamente escalados[1]. Estos parámetros son:
*
Relación Activo circulante/Activo total
*
Relación Activo circulante-Caja/Activo total
* " Activo circulante/deudas
* " Reservas/deudas
* " Beneficio neto/Activo total
* " Beneficio neto/Fondos propios
* " Beneficio neto/Deudas
* " Coste de ventas/Ventas
* " Cash
flow/Deudas
Esencialmente, los tres primeros ratios se hallan
relacionados con la liquidez, mientras los 5, 6 y 7 son ratios de
rentabilidad. Tras cargar en memoria el
fichero de patrones, llamado BANCOS.IN
procedemos a efectuar un proceso de aprendizaje a partir de un mapa sin
entrenar, con pesos iniciales aleatorios.
En este caso mantendremos todos los parámetros de entrenamiento y
características del mapa presentes por defecto (observar cuales son) en el
cuadro de diálogo de "APRENDIZAJE
CON PESOS ALEATORIOS".
Procédase al entrenamiento. Tras
concluir, guardar los pesos con el nombre "BANCOS1.W".
i) Observar la distribución de los patrones (bancos) a lo largo de
las dimensiones del mapa, analizando la formación de grupos de similares
características.
ii) Haciendo uso de la opción Pesos-Análisis,
estudiar la distribución de los valores de los pesos a lo largo del plano. ¿Existe alguna dirección privilegiada? ¿Podría obtenerse información sobre qué
parámetros económicos de los empleados presentan más peso a la hora de estimar
el estado económico de un banco?.
Procedemos ahora a realizar
un "mal entrenamiento" con los mismos patrones de entrada, haciendo
uso de unos parámetros de aprendizaje inadecuados. Modificar de la ventana de diálogo correspondiente al
entrenamiento con pesos aleatorios los siguientes parámetros: límite superior
de inicialización de los pesos, 0.7; límite inferior, -0.7; radio de vecindad,
1; número de iteraciones hasta alcanzar valores de y mínimos, 50 y número total
de iteraciones 100. Mantener iguales
las dimensiones del mapa (10x10) y el ritmo inicial de aprendizaje. Proceder a su entrenamiento, salvando los
pesos al concluir con el nombre "BANCOS2.W". Repetir los puntos (i) e (ii) anteriores con
este nuevo mapa, comparando los resultados.
Bonifacio Martín del Brío y Alfredo Sanz (1997): "Redes Neuronales y Sistemas Borrosos. Introducción Teórica y Práctica", Editorial RA-MA, Madrid, 1997.
Seeción Inteligencia Artificial de la Biblioteca
CiberConta (http://ciberconta.unizar.es/docencia/intelig)
|
|
|
|
|